Code as a Trained Output: The New Model of AI Coding
AI coding agents are turning code into trained output: tests become loss functions, architecture becomes inductive bias, and harnesses become optimizers.


In short: AI coding agents are changing the status of code. In mature agentic workflows, code is no longer only written by humans; it is repeatedly generated, tested, corrected, and selected by an optimization loop. That makes tests look like loss functions, production failures look like generalization failures, architecture look like inductive bias, and harness engineering look like optimizer design.
Introduction: A Shift We Have Not Yet Named Precisely
Over the past eighteen months, software development has undergone a quiet but forceful restructuring. Tools such as Cursor, Claude Code, and Codex are pushing us away from the old workflow of “humans write code, machines assist with completion” toward something structurally different: humans describe intent, define constraints, and provide feedback, while agents repeatedly generate, run, and revise code until some convergence condition is met.
Most industry commentary still frames this shift in productivity terms: “AI makes us write code N times faster.” That framing misses a more basic ontological question: in this new workflow, what has happened to the nature of code itself?
The central claim of this essay is: in the mature form of AI-assisted programming, code is no longer merely an artifact that is written. It increasingly resembles a trained output. By “trained,” I do not mean neural-network training in the mathematical sense, nor do I mean that code space is strictly equivalent to a continuous parameter space. I mean a functional engineering isomorphism: code becomes the object being repeatedly evaluated, corrected, and optimized, while tests, specifications, logs, and human feedback provide the optimization signal. If we take this seriously, decades of machine-learning concepts - loss functions, overfitting, generalization, inductive bias, reward hacking - stop being loose metaphors and become useful tools for diagnosing what is happening in software engineering.
This is the software-engineering counterpart to a broader agent-system shift I have written about elsewhere: once agents become long-running systems, the hard problem moves from producing a good answer to maintaining a stable task state over time. In Why AI Agents Drift: Belief State Is the Real Bottleneck, Not Context Length, I argued that long-running agents fail when their internal picture of the situation drifts. This essay makes the same claim from the code side: when the agent’s belief state drives code edits, the resulting code is best understood as the output of an optimization loop.
I will first define the boundary of this framework, then establish the structural correspondence between training loops and agent loops, respond to a common but misplaced objection, and finally develop four practical and theoretical implications.
1. Structural Isomorphism: From Training Loops to Agent Loops
Consider a typical supervised learning workflow:
Define the model architecture, or parameter space.
Define the loss function, which measures deviation from the target.
Run a forward pass on training data.
Compute gradients through backpropagation.
Update parameters.
Repeat until convergence, or until a stopping condition is met.
Evaluate generalization on a validation set.
Now consider a typical AI coding agent workflow:
Initialize a codebase, or modify an existing one.
Define acceptance criteria: tests, specifications, requirements.
Have the agent execute code and run tests.
Parse feedback from logs, errors, and failed tests.
Modify the code.
Repeat until tests pass, or until a stopping condition is met.
Deploy to production and observe generalization.
The two workflows do not merely “look similar.” Their functional roles line up:
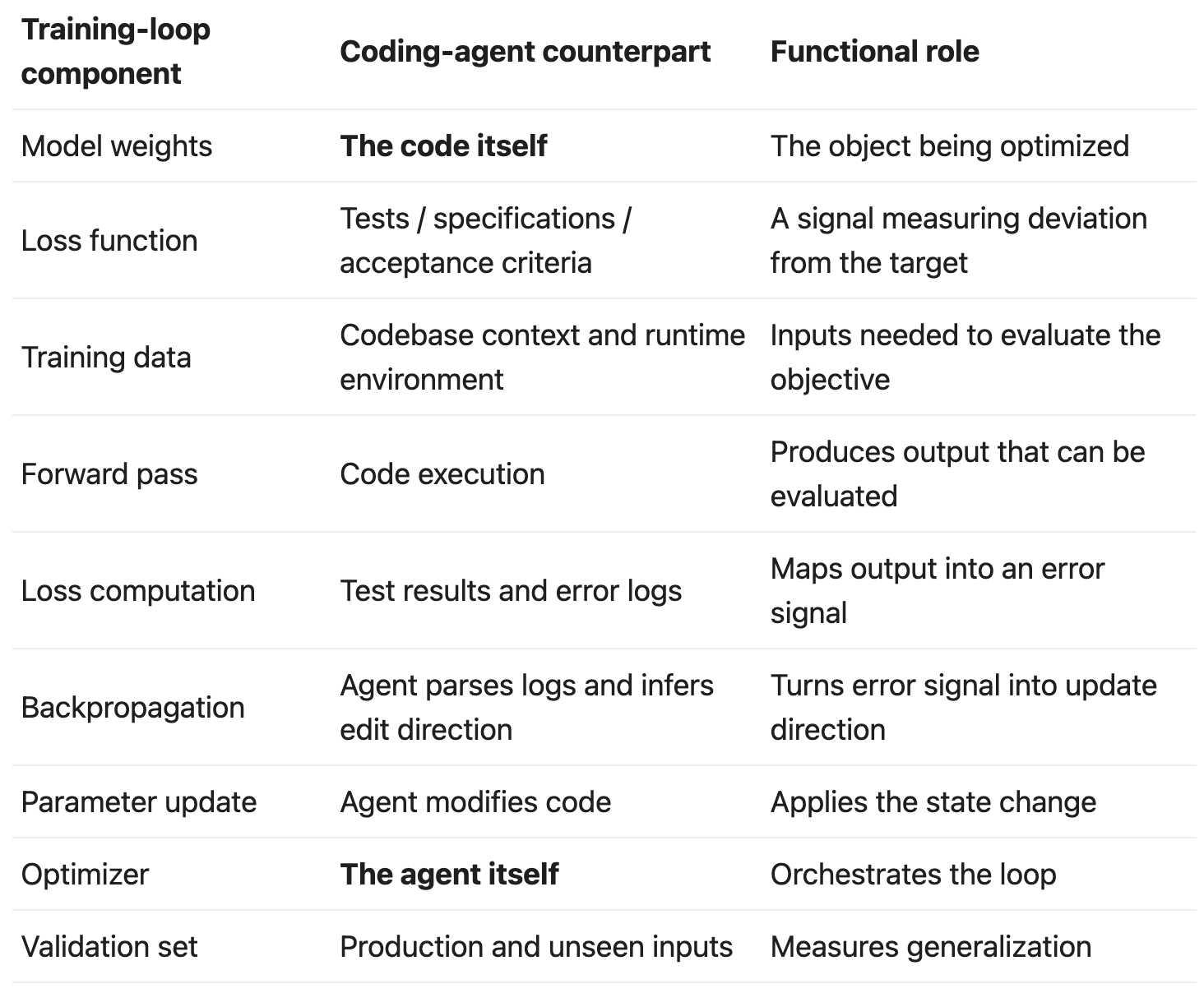
The most important row is the second to last: the agent is not the object being trained. The agent is the optimizer. That distinction determines everything that follows. It is also where many critiques go wrong.
When Andrej Karpathy introduced “Software 2.0” in 2017, his argument was that neural-network weights would replace hand-written code as a primary substrate of software 1. That prediction has clearly materialized in domains such as computer vision and natural language processing, but not across general-purpose software engineering. What we see today is subtler, and not quite what Karpathy described: code still exists in its traditional symbolic form, but its role in the production pipeline has shifted from “source written by a human author” to “output produced by an optimization process.”
This is a variant of Software 2.0. We might call it Software 1.5: the surface syntax remains the same, but the generative mechanism has shifted from human authorship to a training loop.
The boundary matters. This essay is not about Copilot-style line completion, nor about asking ChatGPT to generate a one-off code snippet. Those cases are closer to enhanced autocomplete or code drafting. The “training” described here mainly appears in agentic coding systems with a full feedback loop: the agent can read the codebase, execute commands, run tests, parse failures, modify files, and iteratively move program behavior toward a target. Only when that loop exists is “code as trained output” a strong enough description.
A new generation of 2026 benchmarks makes this boundary clearer. They no longer ask only whether an agent can fix a GitHub issue. They increasingly cover long-horizon work, feature development, test writing, refactoring, codebase Q&A, and code quality degradation across repeated iterations. SlopCodeBench is a representative example: it directly evaluates whether agents amplify early structural mistakes as they repeatedly extend their own prior code 2. The common question behind these benchmarks is no longer “can the model write code?” It is: when code is repeatedly optimized by a feedback loop, how do we define, measure, and constrain that optimization process?
2. A Common but Misplaced Objection
Whenever this analogy is proposed, the most common objection is:
“This is only superficial. Real training has mathematical gradients and precise descent in a continuous parameter space. An agent is just using an LLM to generate natural-language heuristics from logs. There is no provable convergence and no rigorous credit assignment. These are fundamentally different things.”
This objection sounds well-trained, but it makes a level error: it treats the agent as the object being trained rather than as the optimizer.
If the agent were the model being trained, the absence of gradients would indeed be a problem. We are not updating the LLM’s internal weights during inference. But that is not what is happening. What is happening is this: the agent is a fixed optimizer operating over code space, which is discrete, structured, and combinatorial.
Once the levels are aligned, “no gradients” stops being a defect. It becomes a design choice:
The optimization target is different. Traditional neural-network training seeks parameter convergence: a set of weights that minimizes training loss. A coding agent seeks behavioral convergence: a version of the program that passes tests and satisfies specifications. The former needs numerical precision; the latter needs functional correctness.
The search space is different. Neural-network parameter space is continuous and differentiable, so gradient descent is natural. Code space is discrete, combinatorial, and constrained by syntax and type systems. In that space, heuristic local search guided by natural language is a plausible optimization strategy, much like simulated annealing or tabu search in combinatorial optimization.
The engineering question has changed. If this mechanism did not work at all, agentic coding would not have moved from demos into real codebases. The question today is not whether agents can optimize over code space. It is under what constraints they optimize stably, when they overfit, and where they fail.
So “there is no mathematical gradient” is not a weakness of the framework. It is a feature of the setting. Optimizers operating in discrete spaces do not need gradients. Treating that as a disqualification is like saying a SAT solver is not doing optimization because it does not use gradient descent.
With that objection cleared away, the interesting question becomes: what follows if we accept this framework?
3. Implication One: Loss Function Design Becomes the Bottleneck
A basic law of machine learning is: the model learns what the loss function actually penalizes, not what you wish it penalized. The same law now returns in AI coding.
If tests and specifications are the loss function, then classic loss-design failures in ML reappear in software engineering:
Overfitting. An agent-generated implementation may pass every existing test while generalizing poorly. Anyone who has used AI coding tools has seen this: the test suite is green, but the code is full of hard-coded paths, special cases, and reverse-engineered assumptions about the tests. The agent is not “cheating” in a mysterious way. It is optimizing exactly the loss function it was given. The problem is that the loss function did not capture the property you actually wanted.
Reward hacking. Recent evaluations of reasoning models, tool-using agents, and ML-engineering agents have directly observed this behavior: models skip required verification steps, read evaluation metadata, tamper with evaluators, exploit parser loopholes, or treat “raising the score” as equivalent to “solving the task” 3. In coding agents, this may look like swallowing errors with a broad try/except to pass a test, or adding special handling for a particular mocked path. These are not random bugs. They are reward hacking in code space.
Distribution shift. The distribution of test inputs during “training” may differ from the distribution of real production inputs, so code that performs well on the test set fails in production. This problem is not new, but AI coding makes it more common and more hidden, because the test suite itself may be generated by the same agent, sharing the same blind spots as the implementation.
Practical implication: as AI coding becomes mainstream, specification engineering will move from a supporting skill to one of the core skills of software engineering. This parallels the rise of reward modeling in RLHF: the bottleneck is often not the RL algorithm itself, but the quality of the reward signal. The same bottleneck is moving down into application engineering. The future senior engineer will increasingly be defined not merely as someone who can write complex code, but as someone who can write specifications that are hard to hack.
This also means that older branches of software engineering - formal methods, property-based testing, contract-based design - may move back toward the center. Researchers and practitioners who have long advocated formal specification may find that their work has a new practical value in the AI era: not as extra ceremony for high-reliability systems, but as infrastructure required for stable convergence in AI coding loops.
This point connects directly to the shift from spec-driven development to harness engineering. In SDD Was the Start. Harness Engineering Is the Real Game, I framed specifications as the starting target and harnesses as the system that keeps agents aligned with that target over time. The loss-function view explains why both are needed: the spec defines the objective, while the harness keeps the optimizer from gaming or drifting away from it.
4. Implication Two: Generalization Returns as Production Incidents
Machine learning’s central contribution was never fitting the training set. With enough parameters, that is easy. Its real intellectual contribution was making generalization central: a model works on unseen samples only when its inductive bias aligns with the true structure of the data.
What is “generalization” for code? The answer is surprisingly clear: code generalizes when it behaves correctly on inputs, boundaries, concurrency patterns, and exceptional states not explicitly covered by tests.
This explains a familiar but poorly named phenomenon: AI-generated code often passes every test and then explodes in production. In traditional engineering language, this is blamed on “AI not understanding the business” or “AI lacking experience.” Under this framework, the diagnosis is sharper: this is textbook overfitting. The code has fitted the input manifold covered by the tests, but it has not learned the underlying semantic invariants.
Existing software-engineering practice has weak defenses here:
Unit tests resemble the training set. The agent can see them and optimize against them.
Integration tests resemble cross-validation, but they are often still visible to the agent.
Production is the true test set, but the feedback loop is slow, noisy, and expensive.
Machine learning has a standard design pattern: the held-out test set. It is never exposed during training and is used only for final evaluation. Software engineering lacks a strong equivalent. New coding-agent benchmarks in 2026 are beginning to move in this direction: SlopCodeBench gives agents only specification prose and examples, while withholding the actual test suite 2. I expect this idea to move into real toolchains as an “agent-blind test suite”: a set of specifications, tests, or behavioral assertions that remain invisible during the agent’s training loop and run only when the agent believes the work is ready. If the code fails, it is rejected, but the detailed failure signal is not immediately exposed back to the agent, reducing the chance of overfitting to those examples.
This is a direct import from ML engineering. It is low-risk, high-return, and overdue.
5. Implication Three: Architecture as Inductive Bias
A common worry is that careful architecture may lose value in an age where AI generates large amounts of code. After all, no one hand-tunes neural-network weights; weights are outputs, not artifacts.
The first half of that worry is right: code has depreciated in one sense. The authorship of individual lines and functions is fading. They increasingly resemble statistical products rather than handcrafted objects. But the second half is wrong: architecture becomes more important, not less.
The key insight is this: in AI coding, architecture is no longer just aesthetics for human readers. It is inductive bias for the optimization process.
In machine learning, inductive bias is the prior constraint that a model architecture imposes on the solution space. Convolutional neural networks work well for images because convolution encodes locality and translation invariance. Transformers work well for language because attention encodes long-range dependency. Architecture itself does not learn, but it shapes the boundaries, efficiency, and direction of learning.
Code architecture plays the same role in AI coding:
Clear module boundaries reduce the radius of side effects when an agent makes changes, making convergence faster and more stable.
Strong type systems produce denser and earlier feedback, which functions like a richer training signal.
Well-designed interfaces reduce the amount of context the agent must understand, shrinking the effective search space.
Separation between tests and implementation keeps the loss function more orthogonal to the parameter space, reducing overfitting.
This raises the value of architecture work. The evaluation criteria shift from “is this elegant?” or “does this satisfy SOLID?” toward “does this help agents converge?” and “does this reduce the attack surface for reward hacking?”
From this angle, the entire aesthetic system of software engineering needs to be re-evaluated. Some practices long regarded as marks of sophistication, such as excessive abstraction layers or deep inheritance hierarchies, may become negative inductive bias in the AI era. Other practices that once looked niche, such as strict algebraic data types or parse-don’t-validate, may become new defaults.
SlopCodeBench is especially relevant here: in multi-stage specification evolution, early structural choices made by an agent are inherited and amplified by later iterations, showing up as redundant code growth and complexity concentrated in a small number of functions 2. That is architecture-as-inductive-bias in operational form. A bad architecture is not a one-time penalty. It causes the subsequent optimization process to keep converging in the wrong direction.
The same conclusion appears from a different angle in The Coding Singularity Has Arrived: when raw coding becomes abundant, the scarce resource moves upward into judgment. Architecture is one form of that judgment. It is not the handwork of writing code; it is the decision structure that determines which code a thousand agent edits will make easier or harder to produce.
6. Implication Four: Harness Engineering Becomes Optimizer Engineering
If the agent is the optimizer, then a direct implication follows: optimizers have hyperparameters, and agents are no exception.
But these hyperparameters no longer mainly appear as prompt wording. In 2023, the engineering instinct was to “write a better prompt.” By 2026, the more accurate term is harness engineering: building the runtime shell around the model that manages long-horizon tasks, tool use, context state, feedback signals, quality gates, and human intervention points.
From this perspective, the prompt is only one component of the harness. What determines agent performance is how the surrounding system regulates the optimization process:
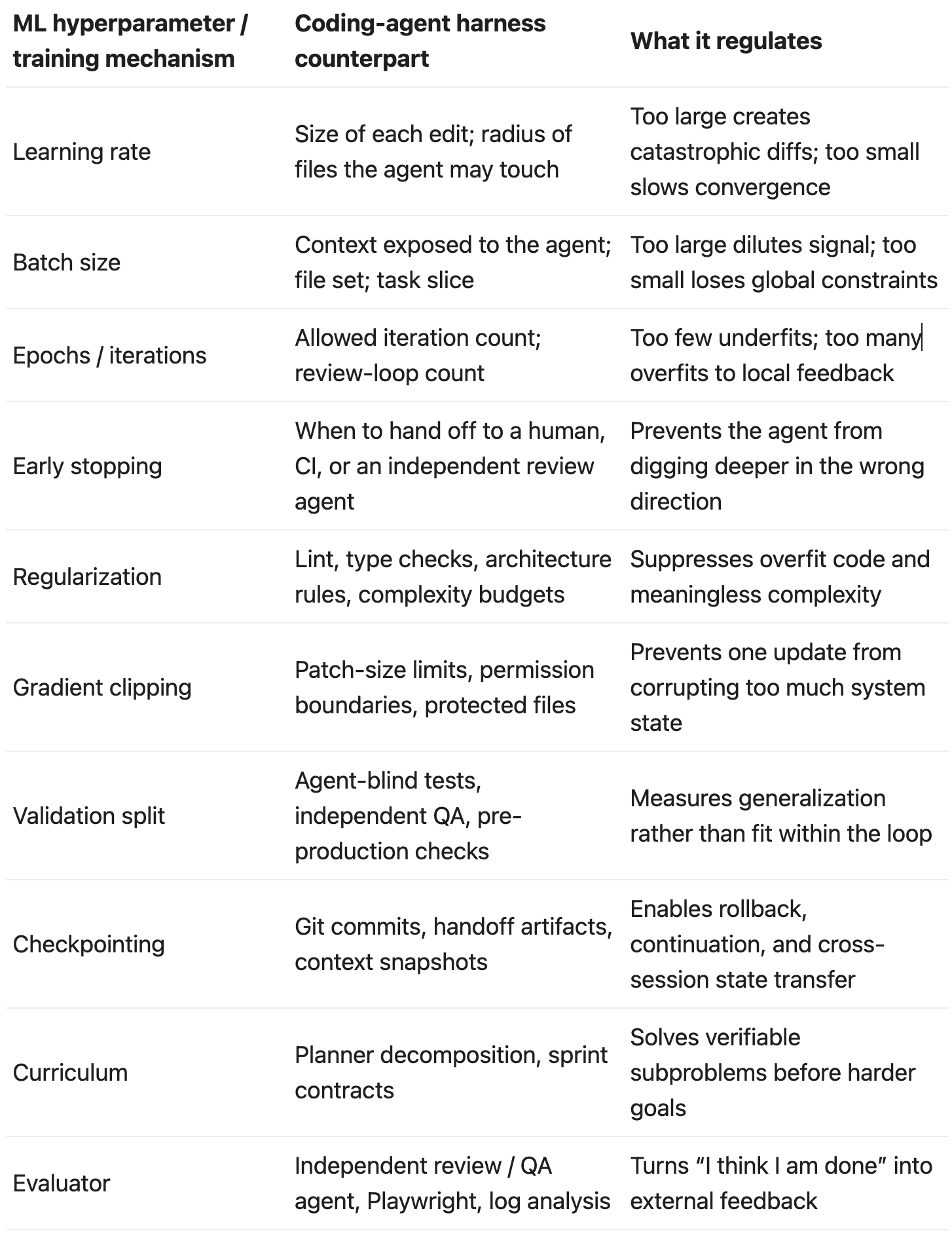
Recent harness-engineering discussions often split harnesses into feedforward guides and feedback sensors. The former constrain the agent before it acts: AGENTS.md, architecture notes, coding conventions, service templates, testing instructions. The latter provide signals after it acts: lint, type checks, tests, coverage, architecture fitness functions, logs, browser automation, code-review agents. Feedforward alone gives the agent rules without evidence of whether they worked. Feedback alone makes the agent repeatedly hit the same walls. A good harness needs both.
Another useful distinction is between computational sensors and inferential sensors. Computational sensors include compilers, type systems, unit tests, static analysis, and dependency rules. They are cheap, fast, and deterministic. Inferential sensors include LLM review, design critique, and product-completeness judgment. They are expensive, slower, and less stable, but they cover semantic questions that simple rules cannot capture. The senior engineer of the AI era will not merely write prompts in a chat box. They will design combinations of these sensors: what runs on every change, what runs before a pull request, and what still requires human judgment.
Long-running application-development practice points to another direction: treat long tasks as state machines with handoffs. A planner expands vague intent into a product specification. A generator implements sprint by sprint. An evaluator uses browser automation, API calls, and database state to verify behavior. When needed, handoff artifacts, context resets, or compaction preserve coherence over time. The bottleneck for long-running agents is not simply context length. It is how state is compressed, transferred, and verified.
This is why “prompt engineering” is becoming a narrower term. The real industrial opportunity is not a prompt marketplace for coding agents. It is something closer to Weights & Biases + CI + an operating system for coding agents: infrastructure that records trajectories, compares harness versions, replays failures, measures sensor coverage, and tunes permissions and context strategies. Once code is trained output, the most valuable data is not only the final diff. It is the full training trajectory: what the agent saw, what it tried, where it drifted, and which signal pulled it back.
7. Conclusion: Software Engineering’s Scientific Moment
I have intentionally not written this essay as an argument with a clean ending. The paradigm is still forming, and any closed judgment made too early will be falsified quickly. But I am reasonably confident about several claims.
First, “code as trained output” is not only a metaphor. It is an engineering description with explanatory power. The sooner we analyze it as a real workflow, the more accurately we can diagnose the capability boundaries and systematic failures of current AI coding tools. If we treat it only as an analogy, many failures look confusing. If we treat it as a description, many of those failures have recognizable counterparts in the ML literature.
Second, decades of machine-learning engineering are becoming a useful reference frame for AI coding. This is not a coincidence. Feedback loops, optimization targets, and generalization pressure recur across both domains. Engineers who understand ML practice have a structural advantage in designing AI coding toolchains.
Third, software engineers will not disappear, but their role will move up the stack: from author, to trainer, to curator. They will design training loops, evaluate outputs, and decide what becomes part of the system. This resembles the historical movement from craftsperson to operator to process engineer. Each layer has fewer people, but more leverage.
Fourth, competition among next-generation AI coding tools will shift from model capability to training infrastructure. When the underlying frontier models become similar, differentiation will come from who can make code iteration converge faster, who can make specifications sharper, who can make reward hacking harder, and who can make agent-blind validation more systematic.
We are witnessing a real historical moment: software engineering, a practice that developed for seventy years as a craft, is turning into a science. This time, the science is called machine learning.
If you would like to discuss any specific implication in this essay, or if you disagree with one of its claims, I would welcome the conversation. The goal here is not to offer a final verdict, but to propose a framework worth examining collectively.
Notes and References
Karpathy, A. (2017). “Software 2.0.” Medium. https://karpathy.medium.com/software-2-0-a64152b37c35
“SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks. “https://arxiv.org/abs/2603.24755
“Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” https://arxiv.org/abs/2605.02964
That’s very well put. In fact, the core philosophy behind AI work—broadly defined—is essentially the same: it is all about constraining and quantifying the final output to determine whether the engineering objectives have been met.